Table of Contents
LLM Infrastructure Cost: Enterprise AI breakdown & Strategic Comparison
Introduction: Rethinking LLM Infrastructure Cost
Most enterprises assume the cost of running LLM infrastructure is primarily driven by GPUs and model inference. That assumption is incomplete. In production environments, the LLM Infrastructure Cost is shaped by an entire system: data pipelines, orchestration layers, reliability mechanisms, and governance controls. Each of these layers introduces its own operational overhead, and more importantly, they compound as usage scales. What begins as a straightforward model deployment quickly evolves into a multi-layered system that requires continuous management, tuning, and monitoring.
As NewFangled Vision observed, a consistent pattern emerges: organizations plan for model costs but end up paying for system complexity. Early estimates focus on tokens and compute, while the real expenses surface later in integration, data movement, and compliance requirements. Understanding this shift from model-centric thinking to system-level cost awareness is essential for enterprises aiming to build scalable and economically viable AI solutions.
The Hidden Reality of the LLM Infrastructure Cost
Before diving into architecture, it is important to ground the discussion in a few practical realities that shape the LLM Infrastructure Cost in enterprise environments:
- Most enterprises underestimate the cost of running LLM infrastructure by 3–5x
- Compute often represents less than half of the total operational cost
- Costs increase rapidly as systems transition from pilot to production scale
These patterns are consistent across industries and use cases. What appears manageable during initial experimentation becomes significantly more complex once the system is exposed to real workloads, users, and enterprise constraints.
In simple terms, running an LLM is not expensive because of a single component it becomes expensive because every supporting layer grows with scale. Data pipelines expand, orchestration becomes more intricate, and governance requirements intensify.
Why the LLM Infrastructure Cost Is Misunderstood
A major reason enterprises miscalculate LLM infrastructure cost is rooted in how they frame the problem. Instead of evaluating the system holistically, they focus on isolated components or simplified assumptions. Three patterns consistently emerge:
1. Over-Focus on Compute
Teams tend to focus on GPU pricing and inference cost because these are easy to measure and benchmark.
- GPU usage and token-based pricing are visible and quantifiable
- Cost calculators and vendor estimates reinforce this focus
However, compute is merely the most obvious aspect of the system and not the most important. As deployments scale, other layers begin to dominate overall costs.
2. Ignoring Lifecycle Costs
LLM systems are not static; to remain successful, they must be maintained on a constant basis.
- Updating and cleaning data sources
- Rebuilding embeddings and indexes
- Refining prompts and workflows
These ongoing activities introduce recurring operational costs that are often excluded from initial planning. Over time, lifecycle costs can exceed the original infrastructure investment.
3. Treating LLMs as APIs Instead of Systems
Many organizations begin with a simplified assumption: “We’ll integrate an LLM API.”
In practice, they end up building:
- A distributed AI system
- Multiple interdependent services
- Several points of failure and monitoring requirements
The change from API integration to system design considerably raises the LLM Infrastructure Cost, both in terms of engineering effort and operational overhead.
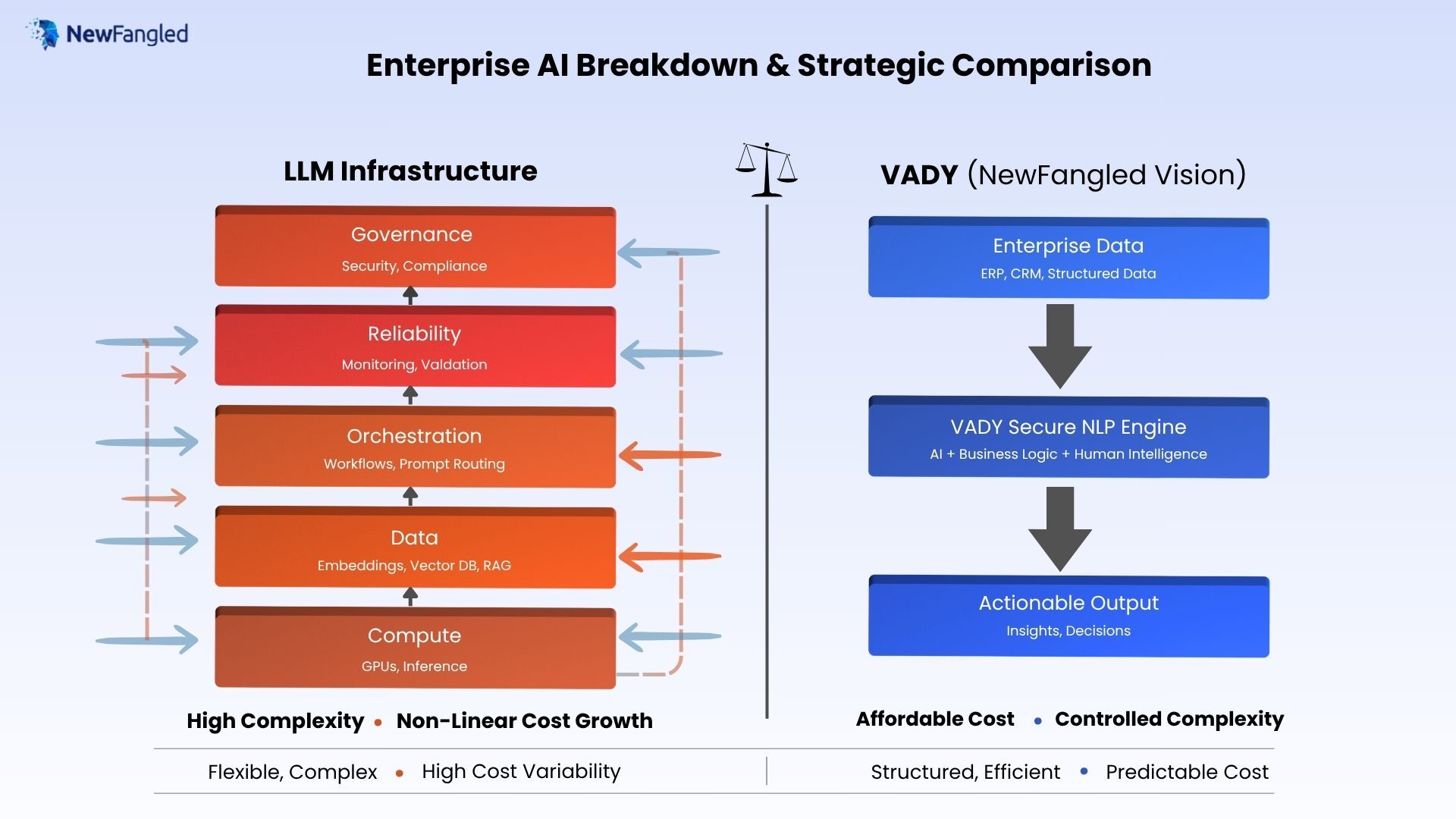
The 5-Layer for LLM Infrastructure Cost
To accurately understand LLM infrastructure Cost breakdown, it is helpful to divide it into layered systems. Consider this a stack: each layer increases capability but also introducing its own cost, dependencies, and operational complexity. As systems scale, these layers do not increase independently; instead, they compound, resulting in a nonlinear overall cost.
1. Compute Layer (The Engine)
Includes:
- GPUs or inference engines
- Real-time and batch processing
Simple view: This is the core engine that powers the model’s ability to generate responses.
Reality:
Compute is often over-provisioned due to unpredictable demand patterns. Enterprises tend to allocate for peak usage, which leads to underutilized resources during normal operation. While compute is the most visible cost component, it is also one of the easier layers to optimize compared to others.
2. Data Layer (The Fuel)
Includes:
- Embeddings
- Vector databases
- Data ingestion pipelines
Simple view: This layer feeds the model with relevant context and knowledge.
Reality:
Data is not static. It requires continuous updating, cleaning, indexing, and reprocessing. As data volumes grow, so do storage, compute, and pipeline costs. In many enterprise deployments, the data layer becomes a long-term cost driver, especially in systems relying on retrieval-augmented generation (RAG).
3. Orchestration Layer (The Coordinator)
Includes:
- Prompt routing
- Workflow logic
- Multi-model handling
Simple view: This layer connects all components and ensures the system behaves as expected.
Reality:
As use cases expand, orchestration becomes increasingly complex. Simple pipelines evolve into multi-step workflows involving multiple models, tools, and data sources. Maintaining and debugging these workflows requires specialized engineering effort, making this layer a significant contributor to operational cost.
4. Reliability Layer (The Safety Net)
Includes:
- Monitoring
- Output validation
- Fallback systems
Simple view: This ensures the system performs consistently and reliably.
Reality:
Enterprise environments require great dependability. This entails creating systems that identify problems, validate outputs, and recover gracefully. These capabilities necessitate more infrastructure, tooling, and engineering investment. While reliability is sometimes disregarded in the early phases, it becomes critical and costly as scale increases.
5. Governance Layer (The Control System)
Includes:
- Security and access control
- Compliance mechanisms
- Data protection
Simple view: This layer ensures the system is secure, compliant, and trustworthy.
Reality:
Governance requirements in enterprises are stringent. Implementing access controls, audit trails, and compliance mechanisms often leads to duplication of infrastructure and added system complexity. In regulated industries, this layer can significantly increase both cost and deployment timelines.
Key Insight
The LLM Infrastructure Cost does not scale linearly. Each layer depends on and amplifies the others:
- More data increases orchestration complexity
- More orchestration requires stronger reliability systems
- More reliability introduces additional governance needs
As a result, what starts as a manageable system can quickly evolve into a complex, multi-layered architecture where costs grow faster than expected.
Understanding this layered model is essential for designing systems that are not only functional, but also economically sustainable.
Understanding LLM Infrastructure: Where the Cost Comes From
LLM infrastructure is designed to deliver high flexibility and advanced reasoning capabilities, making it suitable for complex and evolving enterprise use cases. Unlike traditional systems, it is not limited to predefined rules and can adapt to a wide range of inputs and scenarios.
It excels at:
- Understanding large volumes of unstructured data such as documents, emails, and reports
- Generating human-like responses that feel natural and contextual
- Handling open-ended queries where the expected output is not strictly defined
This makes LLM systems particularly useful for knowledge assistants, research workflows, and decision-support applications.
However, this flexibility introduces additional cost and complexity across the system:
- High compute demand due to large model sizes and inference requirements
- Complex data pipelines, especially in architectures like retrieval-augmented generation (RAG)
- Dynamic orchestration logic to manage prompts, workflows, and multi-step reasoning
Increased governance requirements to manage risks such as hallucinations, data leakage, and compliance
In simple terms:
LLM systems trade higher cost for greater intelligence and flexibility.
As capability increases, so does the need for supporting infrastructure, making the overall system more resource-intensive and operationally complex.
Understanding VADY: A Purpose-Built Alternative
At NewFangled Vision, VADY represents a fundamentally different approach to enterprise AI one that prioritizes decision-making over open-ended generation. Instead of focusing on broad reasoning capabilities, VADY is designed to deliver structured, reliable, and actionable outcomes within business environments.
VADY is a decision intelligence platform built to work with:
- Structured and semi-structured enterprise data such as ERP, CRM, and operational systems
- Defined business workflows and rules
- Real-time insights and actionable recommendations
This makes it particularly effective for operational use cases where consistency and accuracy are critical.
Unlike LLM-based systems, VADY is engineered with a different set of priorities:
- It does not rely heavily on large-scale model inference
- It focuses on deterministic and predictable outputs
- It is optimized for enterprise efficiency, stability, and cost control
Because of this design, VADY reduces the need for complex supporting layers such as heavy data pipelines or dynamic orchestration.
In simple terms:
VADY trades flexibility for efficiency, predictability, and lower cost.
This makes it well-suited for organizations that require dependable, repeatable outcomes without the overhead associated with highly flexible AI systems.
Where VADY Reduces System Complexity
Compared to LLM systems, VADY simplifies several layers of the overall architecture, which directly impacts the cost of deployment and operations. Instead of managing a highly dynamic and complex system, enterprises can work with a more structured and predictable setup.
VADY reduces complexity in the following ways:
- No heavy embedding pipelines in most cases : Eliminates the need for continuous data transformation, indexing, and reprocessing typically required in LLM-based systems
- Reduced need for complex orchestration : Workflows are more structured, minimizing the need for multi-step prompt chaining and model coordination
- More predictable outputs → less validation overhead : Controlled responses reduce the need for extensive output checking, monitoring, and fallback mechanisms
- Lower governance complexity due to controlled responses : With reduced variability, security, compliance, and access control become easier to manage
Because of these simplifications, VADY avoids many of the compounding costs seen in LLM architectures. This results in a system that is easier to maintain, requires less engineering overhead, and delivers a more stable and predictable cost structure for enterprise use cases.
LLM Infrastructure Cost vs VADY Infrastructure
| Dimension | LLM Infrastructure | VADY (NewFangled Vision) |
| Core Purpose | Reasoning & generation | Decision intelligence |
| Data Type | Unstructured heavy | Structured, Unstructured & enterprise data |
| Compute Cost | High (GPU-intensive) | Lower (optimized processing) |
| Output Style | Open-ended | Controlled & actionable |
| System Complexity | High | Moderate |
| Cost Behavior | Non-linear scaling | Predictable scaling |
| Governance Needs | High | More manageable |
| Best Use Cases | Knowledge, reasoning | Business decisions, workflows |
Conclusion
The LLM Infrastructure Cost is not just a pricing question—it is fundamentally an architectural outcome. Looking only at model or compute costs creates a narrow view that often leads to miscalculations as systems scale.
In real-world deployments, cost emerges from how different layers of the system interact, including data pipelines, orchestration logic, reliability mechanisms, and governance requirements. As these layers grow and become more interconnected, complexity increases, and with it, the overall operational cost.
Enterprises that focus only on model-level expenses often encounter unexpected challenges in production. In contrast, those that understand cost as a system-level outcome are better equipped to design efficient and sustainable AI solutions.
At NewFangled Vision, this shift is clear: the future of enterprise AI is not about choosing the most advanced models, it is about designing the right systems that balance performance, control, and cost.
;
![]()
I work at NewFangled Vision, a 6-year-old private GenAI startup from India. We build enterprise-grade AI systems without large LLMs or heavy GPU dependence, with a mission to make AI a seamless, must-have capability for every organization—without complexity or hassle.