Table of Contents
Data Ownership vs Data Access in Enterprise AI: Who Really Controls Your Data?
Introduction: The Misconception at the Center of Enterprise AI
As organizations rapidly deploy generative AI systems across their operations, a common assumption often goes unquestioned: if an AI system only accesses enterprise data, then the organization still fully controls it. On the surface, this assumption seems logical. The company still owns its documents, databases, and internal knowledge repositories. The AI system simply retrieves and processes the data to generate insights. However, the reality of modern AI architecture is more complex. In enterprise AI systems, the difference between data ownership and data access is where many governance, security, and compliance risks emerge.
At NewFangled Vision, we frequently observe organizations approaching AI deployment with a traditional IT mindset. They assume that maintaining ownership of their data automatically ensures full control over how it is used. In practice, AI systems introduce new layers of processing, transformation, and persistence that extend far beyond traditional data access models. Understanding the distinction between data ownership and data access is therefore essential for designing secure and responsible enterprise AI systems.
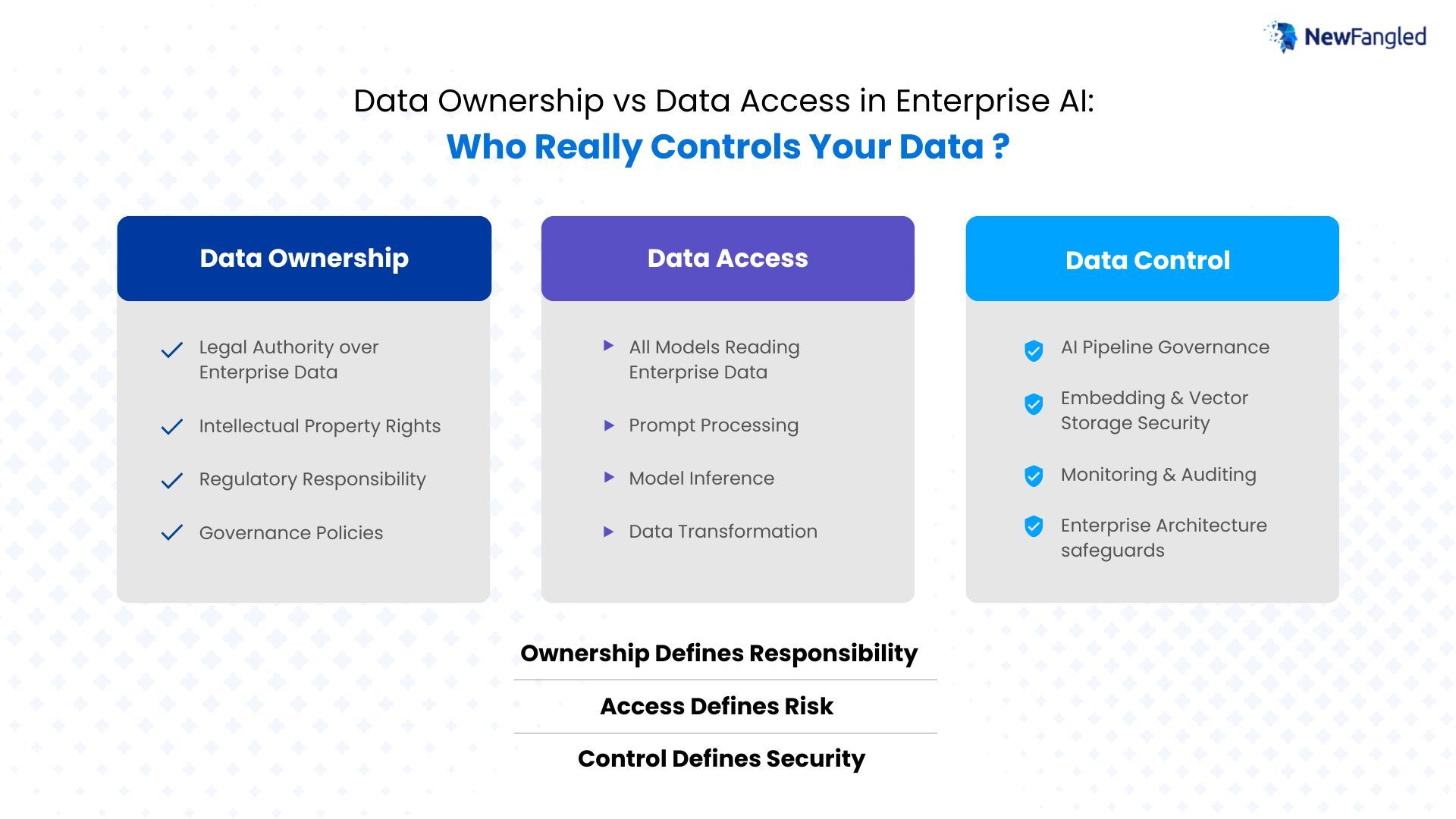
Why Data Ownership Matters in Enterprise AI
Data ownership refers to the legal authority and responsibility over enterprise data assets. Organizations that own their data maintain rights over how that data is stored, governed, and protected. Ownership typically implies accountability in several key areas:
- regulatory compliance
- intellectual property protection
- governance policies
- data lifecycle management
For example, an organization that collects customer information is responsible for protecting that data under privacy regulations and internal governance frameworks. However, while data ownership defines legal responsibility, it does not automatically determine how AI systems interact with the data.
In traditional enterprise systems, ownership and control were often tightly coupled. Data remained inside enterprise infrastructure and was accessed through controlled applications. AI systems operate differently. They often transform enterprise data into new representations that move through multiple components of the AI architecture.
These transformations can include:
- embeddings generated from documents
- prompts sent to language models
- AI-generated summaries or insights
- observability logs containing model interactions
Each of these artifacts represents a new form of data derived from the original dataset. While the organization retains data ownership, these derived artifacts may exist in multiple locations across the AI system. This is where the distinction between ownership and access becomes critical.
Understanding Data Access in AI Systems
Data access refers to the ability of systems or services to read, process, or interact with data. In enterprise AI environments, access is required for models to perform tasks such as retrieving information, answering questions, or generating insights. However, AI systems rarely access data in a static way. Instead, they actively transform data into new formats.
For example, when a generative AI assistant searches enterprise documents, the system may first convert those documents into embeddings. These embeddings are stored in vector databases to enable semantic retrieval. Similarly, prompts sent to language models may contain sensitive information derived from internal data sources. AI systems may also generate new outputs that summarize or reinterpret enterprise data.
These processes mean that data access often creates new data artifacts that persist within AI pipelines. Without careful governance, organizations may maintain legal data ownership while losing visibility into how these artifacts are stored and processed. This is why enterprise AI systems must be designed with clear architectural controls over both ownership and access.
Where AI Systems Blur the Line Between Data Ownership and Access
To understand how these issues arise in practice, it is useful to examine the architecture of modern enterprise AI systems. Several components interact with enterprise data in ways that can complicate governance.
1. AI Model APIs
Many organizations initially integrate AI capabilities through external model APIs. In this scenario, enterprise applications send prompts to large language models hosted by external providers. These prompts often contain internal knowledge, operational data, or confidential documents. Although the organization still legally owns its data, the act of sending prompts to external services raises important questions:
- Are prompts stored by the model provider?
- Are prompts retained in logs or monitoring systems?
- Are prompts used to improve the model?
These questions illustrate how data access mechanisms can introduce new governance challenges even when data ownership remains unchanged.
2. Vector Databases and Embeddings
Generative AI systems frequently rely on vector databases to store embeddings derived from enterprise documents. Embeddings allow AI systems to retrieve relevant information quickly and enable capabilities such as semantic search and retrieval-augmented generation. However, embeddings represent a transformation of enterprise data into a numerical format. While they may not contain raw text, embeddings can still encode sensitive knowledge derived from internal documents.
This raises a critical governance question:
- Who controls these derived data representations?
If embeddings are stored in external systems or shared environments, organizations may inadvertently expose sensitive knowledge despite retaining ownership of the original documents.
3. AI Observability and Logging
AI systems require monitoring to ensure performance, reliability, and quality. Observability platforms track interactions between users, applications, and models. These systems often log prompts, responses, and system metadata. While monitoring tools are essential for debugging and optimization, they can also capture sensitive enterprise information.
For example, prompts used for internal analysis may contain proprietary strategies or confidential operational data. If these logs are stored in external monitoring systems, they can become another layer where enterprise knowledge persists outside controlled environments.
This illustrates why data access in AI systems must be governed across the entire architecture.
The NewFangled Vision Data Control Model
At NewFangled Vision, we approach enterprise AI architecture through the lens of data control across the full AI lifecycle. To address the challenges created by modern AI pipelines, organizations must evaluate their systems across four key dimensions.
1. Data Ownership
Data ownership defines who has legal authority over enterprise data. Organizations remain responsible for protecting their data under regulatory frameworks and internal governance policies. Ownership establishes accountability but does not guarantee control over how AI systems interact with the data.
2. Data Access
Data access determines which systems or services can interact with enterprise data.
This includes:
- reading documents
- retrieving records from databases
- generating embeddings
- processing prompts
Controlling data access ensures that only authorized systems can interact with enterprise information.
3. Data Processing
AI systems often transform enterprise data into new formats.
Examples include:
- embeddings created from documents
- summaries generated by AI models
- structured insights derived from datasets
These transformations extend the lifecycle of enterprise data beyond its original form. Organizations must ensure that governance policies apply not only to raw data but also to these derived artifacts.
4. Data Persistence
AI pipelines frequently generate new artifacts that persist within the system.
These may include:
- vector database entries
- cached model responses
- prompt logs
- monitoring data
Ensuring secure storage and governance of these artifacts is essential for protecting enterprise data ownership.
Why the Distinction Matters for Enterprises
Understanding the difference between data ownership and data access has significant implications for enterprise AI adoption.
1. Compliance and Regulatory Risk
Organizations must comply with regulations governing personal data, financial information, and industry-specific standards. If AI systems process sensitive data without proper controls, organizations may inadvertently violate compliance requirements.
2. Intellectual Property Exposure
Enterprise knowledge often represents valuable intellectual property. AI systems that process internal data may generate insights, embeddings, or summaries that reveal strategic information. Protecting these artifacts is essential for preserving the value of enterprise data ownership.
3. Governance and Transparency
Without visibility into how AI systems access and process data, organizations may struggle to enforce governance policies. Clear architectural controls help ensure that enterprise data remains secure throughout the AI lifecycle.
Conclusion: Data Ownership Defines Responsibility, Access Defines Risk
As generative AI continues to reshape enterprise technology, organizations must rethink how they manage their data. While enterprises may retain data ownership, the ways in which AI systems access and transform that data can create new governance challenges.
From the NewFangled Vision perspective, enterprise AI systems must be designed with architectural controls that extend across the entire data lifecycle.
Ownership defines responsibility.
Access defines risk.
Organizations that understand this distinction will be better prepared to deploy AI systems that are secure, compliant, and trustworthy.
By aligning data ownership policies with modern AI architecture practices, enterprises can unlock the benefits of AI while maintaining control over their most valuable asset: their data.
![]()
I work at NewFangled Vision, a 6-year-old private GenAI startup from India. We build enterprise-grade AI systems without large LLMs or heavy GPU dependence, with a mission to make AI a seamless, must-have capability for every organization—without complexity or hassle.