Table of Contents
Why GenAI Adoption Struggles in Enterprise Environments?
Introduction
In the previous post, we looked at why enterprise GenAI adoption slows as excitement fades into worries about trust, governance, security, and accountability. Cloud APIs were simple to use at first, but harder to trust as they scaled. Learn more here: https://newfangled.io/blog/the-enterprise-journey-to-genai-from-excitement-to-reality/.
As businesses come to terms with this fact, many believe the issue comes in determining the best adoption path. If public cloud GenAI poses a risk, then alternatives such as Retrieval-Augmented Generation (RAG) or on-premises open-source models must provide a safer path ahead.
In practice, however, these approaches impose their own limits. As organisations delve deeper into GenAI adoption, they learn that the issue is not access to models, but rather how GenAI is operationalised. The article investigates why the most prevalent GenAI adoption plans fall short, and what these implications are for businesses planning the next stage.
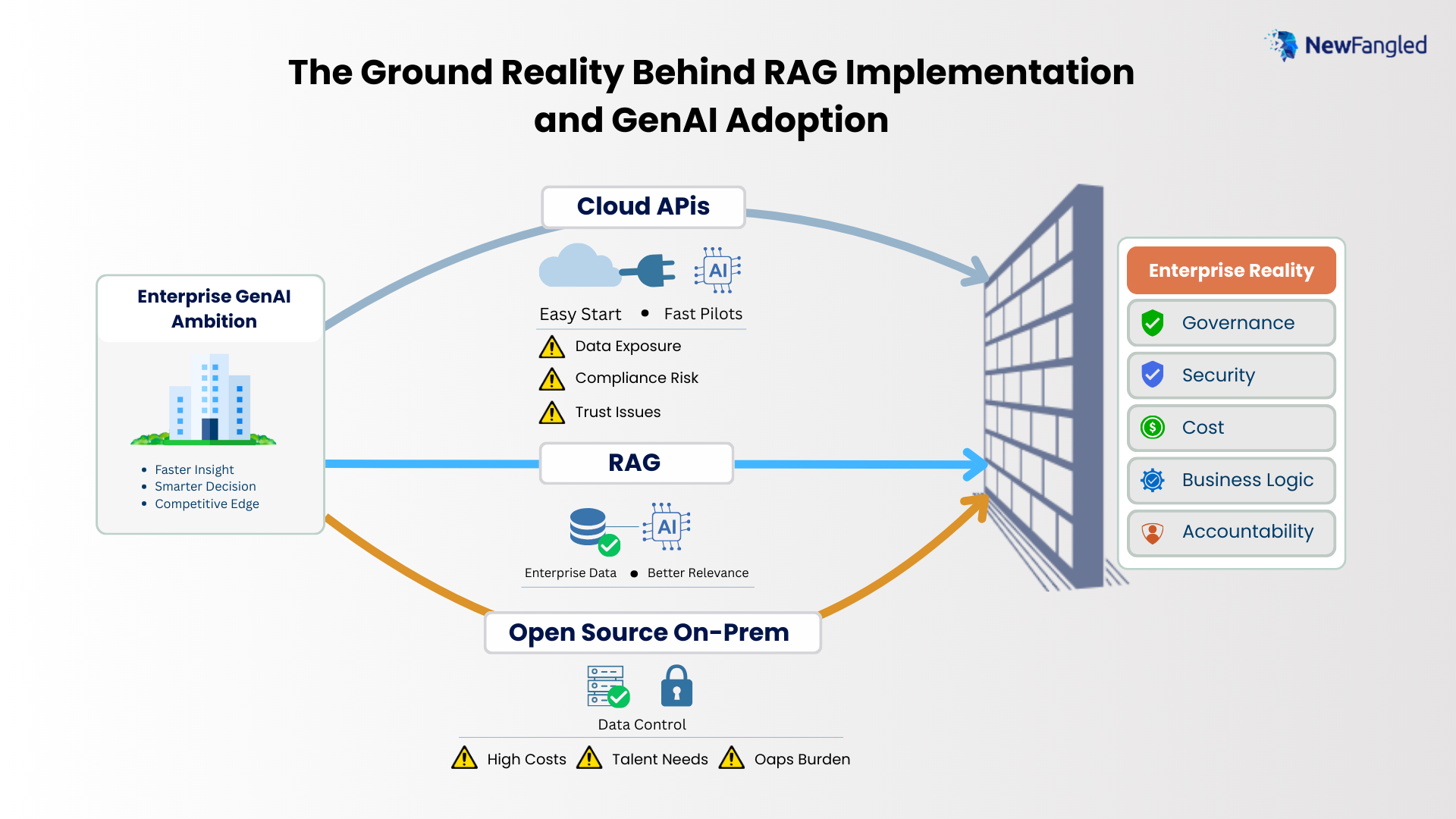
RAG as a GenAI Adoption Strategy: Promise vs. Practice
Retrieval-Augmented Generation (RAG) has become one of the most popular enterprise GenAI implementation methodologies. The concept is simple: rather than relying solely on a model’s training data, organisations obtain relevant internal information and include it into the model’s context.
On paper, RAG addresses multiple enterprise concerns:
- It integrates company data with AI-generated replies.
- It improves the contextual relevance.
- It provides natural language access to analytics and support systems.
- It appears to minimise hallucinations by anchoring the reactions.
Many organisations see RAG as a natural progression from basic cloud API usage. It promises better answers without requiring full model ownership, making it appealing for companies looking to accelerate GenAI deployment.
However, the situation is more complicated. Large corporate schemas quickly exceed token restrictions. Business logic joins, metrics, validation rules, and decision hierarchies frequently live outside of retrievable documents. As a result, RAG systems struggle to answer issues that involve system-level reasoning rather than mere retrieval.
The Hidden Cost of RAG: Complexity Without Control
As RAG implementations advance, organisations face additional problems that directly impact GenAI adoption at scale.
Enterprises confront the following key restrictions using RAG:
- Scalability limits as data volume and schema complexity increase.
- Business logic gaps occur when retrieved data lacks operational context.
- Persistent hallucination danger when the context is lacking.
- Increased engineering overhead for managing pipelines, embeddings, and retrieval layers
More importantly, RAG does not prevent data exposure. In many systems, data continues to flow to cloud-hosted models, reintroducing the trust and compliance issues that corporations intended to address.
This results in a typical scenario: RAG enhances early demos but problems in production. Expectations rise quicker than reliability, reducing user trust. What looks to be a control tool becomes an additional layer of infrastructure that businesses must secure, administer, and maintain.
Open-Source LLMs: The “Secure” GenAI Adoption Illusion
As a result, many businesses are shifting to open-source foundation models like LLaMA, Mistral, or Falcon, which can be implemented on-premises or in private clouds. This technique is commonly referred to as the “secure path” to GenAI adoption.
The appeal is evident.
- Enterprise data remains within organisational boundaries.
- Frameworks are open, flexible.
- Teams experience a stronger sense of ownership.
However, firms swiftly face operational reality.
A common misconception is that on-prem or open-source GenAI becomes economical at modest scale. In reality, even moderate usage introduces significant operational cost and complexity:
- Infrastructure costs quickly reach $10,000–$15,000 per month for roughly 50 concurrent users with latency expectations of 1–3 seconds
- Specialized talent becomes mandatory, including ML engineers, MLOps specialists, and infrastructure experts
- Security, monitoring, and compliance responsibilities shift entirely to the enterprise, with no managed safety net
- Model lifecycle management upgrades, performance tuning, and incident response must be handled in-house
Despite this, the models remain general foundation models. They are not familiar with enterprise-specific workflows, policies, or domain expertise.
The Data Tells a Clear Story About GenAI Adoption Risk
Industry data reinforces what enterprises are experiencing on the ground.
- 44% of surveyed enterprises report adverse GenAI impacts related to accuracy, privacy, or IP risk (McKinsey).
- 80% of businesses still lack a plan for AI-related risk or crisis management (Forbes).
- 90% of CIOs say concerns about AI costing more than expected limit their ability to realize value (Gartner).
These data underscore an important point: GenAI adoption is not stalled owing to a lack of technology. It is failing owing to issues with governance, cost predictability, and operational readiness.
Enterprises understand that “owning the model” does not imply “owning the solution.” Without established processes, risk frameworks, and architectural control, GenAI becomes another complex system that is costly to operate and impossible to trust.
The Big Realization: Foundation Models Are Not the Destination
As organisations explore cloud APIs, RAG, and open-source models, they realise that all of these approaches lead back to foundation models. Yes, powerful, but it is essentially general.
Foundation models mimic raw engines. They provide capabilities but not direction. However, enterprises do not follow generic logic. They require:
- Domain-specific intelligence
- tailored summaries linked with the business context.
- Integration with real operational workflows
- Complete data ownership and governance.
GenAI deployment at the enterprise level demands more than just access to models. It necessitates structures that incorporate business logic, impose control, and grow with organisational knowledge.
This realization is a turning point. Enterprises should stop asking “Which model should we use?” and instead ask “How should intelligence exist inside the enterprise?”
Conclusion
The enterprise GenAI journey has reached a critical point. Cloud APIs facilitated experimentation but raised trust problems. RAG promised relevance but increased complexity. Open-source methods provided perceived control while shifting expense and risk inward.
Each phase exposed the same underlying truth: long-term GenAI adoption is about control, governance, and business-specific intelligence rather than faster model access. As businesses rethink their GenAI adoption strategy, one question now defines the way forward:
So, how can organisations implement GenAI while maintaining control, staying within budget, and providing business-specific intelligence?
![]()
I work at NewFangled Vision, a 6-year-old private GenAI startup from India. We build enterprise-grade AI systems without large LLMs or heavy GPU dependence, with a mission to make AI a seamless, must-have capability for every organization—without complexity or hassle.